2014-01-13
#1
好,多谢开帖!欢迎以后也多来HLLVM群组参与讨论。
普及一下背景知识。楼主问的是HotSpot VM中的Serial GC,特别是其中的minor GC的实现细节。Minor GC只收集young generation,而使用Serial GC时这个young generation的实现类叫做DefNewGeneration。
关于这些DefNew啊ParNew啊啥的名字的历史,可以参考我之前写的一帖:http://hllvm.group.iteye.com/group/topic/37095#post-242695
FastScanClosure只在DefNewGeneration的收集中有用到。
HotSpot VM里有很多以*-Closure方式命名的类。它们其实是封装起来的回调函数。为了让GC的具体逻辑与对象内部遍历字段的逻辑能松耦合,这部分都是通过回调函数来连接到一起的。ScanClosure与FastScanClosure都可用于DefNewGeneration的扫描。
顺带一提,之前jianglei3000在HLLVM群组发表过一篇新生代回收调试的一些心得,说的正好就是Serial GC的minor GC,值得配合本文一读。
===============================================
然后从基本入手。HotSpot VM Serial GC的minor GC使用的是Cheney算法的变种,所以先理解基本的Cheney算法有助理清头绪。
说啥都没代码直观,先上代码:星期天陪老婆去理发的时候有空闲写了个Cheney算法的伪代码:https://gist.github.com/rednaxelafx/8412637
这个伪代码采用近似C++的语法,其实稍微改改就能实际运行。
这个算法的原始论文是C. J. Cheney在1970年发表的:A nonrecursive list compacting algorithm
该算法在很多书上都有讲解,例如在《The Garbage Collection Handbook》第44页,第4章4.1小节、《ガベージコレクションのアルゴリズムと実装》第4章4.4小节。每个版本的算法描述都稍微不同,我的伪代码也跟这两本书写的方式稍微不同,但背后要表达的核心思想是一样的就OK了。
Tracing GC的核心操作之一就是从给定的根集合出发去遍历对象图。对象图是一种有向图,该图的节点是对象,边是引用。遍历它有两种典型顺序:深度优先(DFS)和广度优先(BFS)。
广度优先遍历的典型实现思路是三色遍历:给对象赋予白、灰、黑三种颜色以标记其遍历状态:
* 白色:未遍历到的对象
* 灰色:已遍历到但还未处理完的对象(意味着该对象尚有未遍历到的出边)
* 黑色:已遍历完的对象
从Wikipedia引用一张动画图来演示三色遍历:
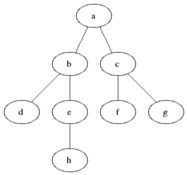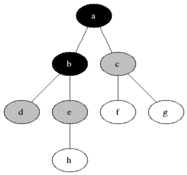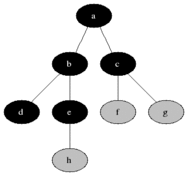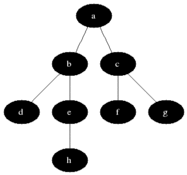
遍历过程:
1. 一开始,所有对象都是白色的;
2. 把根集合能直接碰到的对象标记为灰色。在只有一个根对象的地方就只要把那个对象标记为灰色。但GC通常不是只有一个特定根对象,而是有一个集合的引用作为根,这些引用能直接碰到的对象都要标记为灰色。
3. 然后逐个扫描灰色对象的出边,把这些边能直接碰到的对象标记为灰色。每当一个对象的所有出边都扫描完了,就把这个对象标记为黑色。
4. 重复第3步直到不再有灰色对象,遍历结束。
这黑白灰要怎么跟实际实现联系起来呢?基本算法会使用一个队列(queue)与一个集合(set):
在这种伪代码中,队列scanning与集合scanned组合起来记录了对象的颜色:
* 所有没进入过scanning队列的对象是白色的;
* 进入了scanning队列与scanned集合,但还没离开scanning队列的对象是灰色的;
* 离开了scanning队列并且在scanned集合里的对象是黑色的。
假如对象内可以记录遍历状态的话,那算法可以变为只用一个队列:
上面两个版本是有且只有一个特殊对象作为根对象的有向图的广度优先遍历。假如不是这样而是有一个集合的引用作为根的话,算法会变为:
有没有觉得这算法的样子跟GC越来越像了?
Cheney算法正如上面说的一样,用一个队列来实现对象图的遍历。比较完整的伪代码可以参考我发这节开头给的链接,其中核心的部分抽取出来如下:
它的设计非常精妙:
1. 它使用一块连续的地址空间来实现GC堆,并将其划分为2个半分空间(semispace),分别称为from-space与to-space。平时只用其中一个,也就是from-space;
2. 逐个扫描指针,每扫描到一个对象的时候就把它从from-space拷贝到to-space,并在原来的对象里记录下一个转发指针(forwarding pointer),记住该对象被拷贝到哪里了。要知道一个对象有没有被扫描(标记)过,只要看该对象是否有转发指针即可;
3. 每扫描完一个指针就顺便把该指针修正为指向拷贝后的新对象。这样,对象的标记(mark)、整理(compaction)、指针的修正就合起来在一步都做好了;
4. 它不需要显式为扫描队列分配空间,而是复用了to-space的一部分用作隐式队列。用一个scanned指针来区分to-space的对象的颜色:在to-space开头到scanned指针之间的对象是黑色的,在scanned指针到to-space已分配对象的区域的末尾之间的对象是灰色的。如何知道还有没有灰色对象呢?只要scanned追上了to-space已分配对象区域的末尾就好了。
这种做法也叫做“两手指”(two-finger):“scanned”与“free”。只需要这两个指针就能维护隐式扫描队列。“free”在我的伪代码里就是to_space->top()。
Cheney算法GC工作时,to-space中各指针的样子如下:
在GC结束时,不需要对原本的from-space做什么清理动作,只要把它的分配指针(top)设回到初始位置(bottom)即可。之前在里面的对象就当作不存在了。自然,也就不需要清理其中设置了的转发指针。
要想看图解Cheney算法的工作过程的,请参考这个幻灯片:http://www.ps.uni-saarland.de/courses/gc-ws01/slides/copying_gc.pdf
我现在懒得画图…这个幻灯片已经画得足够好了,直接看它吧。
(不过它所图解的过程跟我的伪代码有一点点细微的差异,别介意…)
后面的回复LeafInWind问道:
while的条件就是scanned < to_space->top()。或者说条件是scanned != to_space->top()也行。反正就是:如果scanned还没追上to_space->top(),继续循环。
scanned是一个指针,*scanned是一个Object实体。只有指针可以等于null,对象实体就是一个实在的东西,不可能是“null”。
--------------------------------------------------------------
Cheney算法是一个非常非常简单且高效的GC算法。看前面我写的伪代码就可以有直观的感受它有多简单。它的实现代码恐怕比简易mark-sweep还简单。
但为啥很多简易的VM宁可采用mark-sweep而不用Cheney算法的copying GC呢?
因为mark-sweep GC的常规实现不移动对象,而copying GC必须移动对象。移动对象意味着使用GC的程序(术语叫做mutator)需要做更多事情,例如说要能准确定位到所有的指针,以便在对象移动之后修正指针。很多简易VM都偷懒不想记住所有指针的位置,所以无法支持copying GC。
关于找指针的问题,我之前也写过一点:找出栈上的指针/引用
有一种叫做Bartlett风格的mostly-copying GC可以弱化定位指针的需求:根集合之中不需要准确定位指针,只要保守的扫描;在GC堆内的对象则必须要能准确定位其中的指针。有兴趣的可以参考其原始论文:Mostly-Copying Garbage Collection Picks Up Generations and C++
--------------------------------------------------------------
Cheney算法的简单优雅之处来自它通过隐式队列来实现广度优先遍历,但它的缺点之一却也在此:广度优先的拷贝顺序使得GC后对象的空间局部性(memory locality)变差了。但是如果要改为真的深度优先顺序就会需要一个栈,无论是隐式(通常意味着递归调用)或者是显式。
使用递归实现的隐患是容易爆栈,有没有啥办法模拟深度优先的拷贝顺序但不用栈呢?这方面有很多研究。其中一种有趣的做法是IBM的hierarchical copying GC,参考:Improving Locality with Parallel Hierarchical Copying GC
===============================================
相比基本的Cheney算法,HotSpot VM Serial GC有什么异同呢?
相同点:
1. 使用广度优先遍历;
2. 使用隐式队列;
3. copy等同mark + relocate (compact) + remap (pointer fixup)三件事一步完成。
在HotSpot VM里,copying GC用了scavenge这个名字,说的是完全相同的事。
相异点:
1. 基本Cheney算法不分代,而HotSpot的GC分两代
2. 基本Cheney算法使用2个半分空间(semispace),而HotSpot的GC在young generation使用3个空间——1个eden与两个survivor space。注意这两个survivor space就与semispace的作用类似。
在G1 GC之前,所有HotSpot VM的GC堆布局都继承自1984年David Ungar在Berkeley Smalltalk里所实现的Generation Scavenging。参考论文:Generation Scavenging: A Non-disruptive High Performance Storage Reclamation Algorithm
GC堆布局:
那我们一点点把基本的Cheney算法映射过来。
* 基本Cheney算法用from-space和to-space,而HotSpot VM的DefNewGeneration有三个空间,eden space、from-space、to-space。后者的eden space + from-space大致等于前者的from-space,而后者的to-space + old gen的一部分大致等于前者的to-space。
* 拷贝对象的目标空间不一定是to-space,也有可能是old generation,也就是对象有可能会从young generation晋升到old generation。
为了实现这一功能,对象头的mark word里有一小块地方记录对象的年龄(age),也就是该对象经历了多少次minor GC。如果扫描到一个对象,并且其年龄大于某个阈值(tenuring threshold),则该对象会被拷贝到old generation;如果年龄不大于那个阈值则拷贝到to-space。
要留意的是,基本Cheney算法中2个半分空间通常一样大,所以可以保证所有from-space里活着的对象都能在to-space里找到位置。但HotSpot VM的from-space与to-space通常比eden space小得多,不一定能容纳下所有活的对象。如果一次minor GC的过程中,to-space已经装满之后还遇到活对象要拷贝,则剩下的对象都得晋升到old generation去。这种现象叫做过早晋升(premature tenuring),要尽量避免。
* 既然拷贝去的目标空间不一定是to-space,那原本Cheney算法里的隐式扫描队列会在哪里?
答案是既在to-space,也在old generation。很简单,在这两个空间都记录它们的scanned指针(叫做“saved mark”),这俩空间各自原本也记录着它们的分配指针(“top”),之间的部分就用作扫描队列。
* Forwarding pointer安装在对象(oopDesc)头部的mark word(markOop)里。只有在minor GC的时候才会把已拷贝的对象的mark word借用来放转发指针。
* 通过回调,把遍历逻辑与实际动作分离。例如说,遍历根集合的逻辑封装在GenCollectedHeap::gen_process_strong_roots()、SharedHeap::process_strong_roots()里,遍历对象里的引用类型字段的逻辑封装在oopDesc::oop_iterate()系的函数里;而实际拷贝对象的动作则由FastScanClosure::do_work()负责调用。
* 基本Cheney算法的“scanned”指针,在HotSpot Serial GC里是每个space的“saved mark”。相关操作的函数名是:“save_marks()” / “set_saved_mark()”、“reset_saved_mark()”、“no_allocs_since_save_marks()” / “saved_mark_at_top()”
看看遍历循环的结束条件(循环条件的反条件):
跟基本Cheney算法的循环条件 scanned != top() 一样。
为啥我的伪代码里scanned是个局部变量,而HotSpot里变成了每个空间的成员字段?因为使用回调函数来分离遍历逻辑与实际动作,代码结构变了,这个scanned指针也只好另找地方放来让需要访问它的地方都能访问到。
* HotSpot VM的分代式GC需要通过写屏障(write barrier)来维护一个记忆集合(remember set)——记录从old generation到young generation的跨代引用的数据结构。具体在代码中叫做CardTable。在minor GC时,old generation被remember set所记录下的区域会被看作根集合的一部分。而在minor GC过程中,每当有对象晋升到old generation都有可能产生新的跨代引用。
所以FastScanClosure::do_work()里也有调用写屏障的逻辑:OopsInGenClosure::do_barrier()。
* HotSpot VM要支持Java的弱引用。在GC的时候有些特殊处理要做。可以参考这帖:http://hllvm.group.iteye.com/group/topic/27945?page=2#post-209812
* HotSpot VM的GC必须处理一些特殊情况,一个极端的例子是to-space和old generation的剩余空间加起来都无法容纳eden与from-space的活对象,导致GC无法完成。这使得许多地方代码看起来很复杂。但要了解主要工作流程的话可以先不关心这些旁支逻辑。
--------------------------------------------------------------
HotSpot代码与我的伪代码的几个对应关系:
HotSpot => 我的Cheney算法伪代码
* saved mark => scanned
* FastScanClosure => process_reference()
* GenCollectedHeap::gen_process_strong_roots()、SharedHeap::process_strong_roots() => 遍历根集合的循环逻辑
* FastEvacuateFollowersClosure => 遍历扫描队列的循环
* oopDesc::oop_iterate() => 遍历对象的引用类型字段的循环,Object::object_fields()
* DefNewGeneration::copy_to_survivor_space() => 拷贝对象的逻辑,Heap::evacuate()
其它应该都挺直观的?
===============================================
Oracle Labs的Maxine VM里也有过Cheney算法的实现,在这里:https://kenai.com/projects/maxine/sources/maxine/content/com.oracle.max.vm/src/com/sun/max/vm/heap/sequential/semiSpace/SemiSpaceHeapScheme.java?rev=8747
也可以参考来看看。纯Java实现的GC喔。
===============================================
顺带一提,早期V8的分代式GC中的minor GC也是基于Cheney算法,而且更接近原始的基本算法——只用2个半分空间。最大的区别就是由于是分代式GC的一部分,它也跟HotSpot一样要处理对象晋升和写屏障。
Jay Conrod:A tour of V8: Garbage Collection(中文翻译:V8 之旅: 垃圾回收器)
就先写这么多了⋯
普及一下背景知识。楼主问的是HotSpot VM中的Serial GC,特别是其中的minor GC的实现细节。Minor GC只收集young generation,而使用Serial GC时这个young generation的实现类叫做DefNewGeneration。
关于这些DefNew啊ParNew啊啥的名字的历史,可以参考我之前写的一帖:http://hllvm.group.iteye.com/group/topic/37095#post-242695
FastScanClosure只在DefNewGeneration的收集中有用到。
HotSpot VM里有很多以*-Closure方式命名的类。它们其实是封装起来的回调函数。为了让GC的具体逻辑与对象内部遍历字段的逻辑能松耦合,这部分都是通过回调函数来连接到一起的。ScanClosure与FastScanClosure都可用于DefNewGeneration的扫描。
顺带一提,之前jianglei3000在HLLVM群组发表过一篇新生代回收调试的一些心得,说的正好就是Serial GC的minor GC,值得配合本文一读。
===============================================
然后从基本入手。HotSpot VM Serial GC的minor GC使用的是Cheney算法的变种,所以先理解基本的Cheney算法有助理清头绪。
说啥都没代码直观,先上代码:星期天陪老婆去理发的时候有空闲写了个Cheney算法的伪代码:https://gist.github.com/rednaxelafx/8412637
这个伪代码采用近似C++的语法,其实稍微改改就能实际运行。
这个算法的原始论文是C. J. Cheney在1970年发表的:A nonrecursive list compacting algorithm
该算法在很多书上都有讲解,例如在《The Garbage Collection Handbook》第44页,第4章4.1小节、《ガベージコレクションのアルゴリズムと実装》第4章4.4小节。每个版本的算法描述都稍微不同,我的伪代码也跟这两本书写的方式稍微不同,但背后要表达的核心思想是一样的就OK了。
Tracing GC的核心操作之一就是从给定的根集合出发去遍历对象图。对象图是一种有向图,该图的节点是对象,边是引用。遍历它有两种典型顺序:深度优先(DFS)和广度优先(BFS)。
广度优先遍历的典型实现思路是三色遍历:给对象赋予白、灰、黑三种颜色以标记其遍历状态:
* 白色:未遍历到的对象
* 灰色:已遍历到但还未处理完的对象(意味着该对象尚有未遍历到的出边)
* 黑色:已遍历完的对象
从Wikipedia引用一张动画图来演示三色遍历:
遍历过程:
1. 一开始,所有对象都是白色的;
2. 把根集合能直接碰到的对象标记为灰色。在只有一个根对象的地方就只要把那个对象标记为灰色。但GC通常不是只有一个特定根对象,而是有一个集合的引用作为根,这些引用能直接碰到的对象都要标记为灰色。
3. 然后逐个扫描灰色对象的出边,把这些边能直接碰到的对象标记为灰色。每当一个对象的所有出边都扫描完了,就把这个对象标记为黑色。
4. 重复第3步直到不再有灰色对象,遍历结束。
这黑白灰要怎么跟实际实现联系起来呢?基本算法会使用一个队列(queue)与一个集合(set):
void breadth_first_search(Node* root_node) {
// 记录灰色对象的队列
Queue<Node*> scanning;
// 记录黑色对象的集合
Set<Node*> scanned;
// 1. 一开始对象都是白色的
// 2. 把根对象标记为灰色
scanned.add(root_node);
scanning.enqueue(root_node);
// 3. 逐个扫描灰色对象的出边直到没有灰色对象
while (!scanning.is_empty()) {
Node* parent = scanning.dequeue();
for (Node* child : parent->child_nodes() { // 扫描灰色对象的出边
// 如果出边指向的对象还没有被扫描过
if (child != nullptr && !scanned.contains(child)) {
scanned.add(child); // 记录下它已经被扫描到了
scanning.enqueue(child); // 也把该对象放进灰色队列里等待扫描
}
}
}
}在这种伪代码中,队列scanning与集合scanned组合起来记录了对象的颜色:
* 所有没进入过scanning队列的对象是白色的;
* 进入了scanning队列与scanned集合,但还没离开scanning队列的对象是灰色的;
* 离开了scanning队列并且在scanned集合里的对象是黑色的。
假如对象内可以记录遍历状态的话,那算法可以变为只用一个队列:
void breadth_first_search(Node* root_node) {
// 记录灰色对象的队列
Queue<Node*> scanning;
// 1. 一开始对象都是白色的
// 2. 把根对象标记为灰色
root_node->set_marked();
scanning.enqueue(root_node);
// 3. 逐个扫描灰色对象的出边直到没有灰色对象
while (!scanning.is_empty()) {
Node* parent = scanning.dequeue();
for (Node* child : parent->child_nodes() { // 扫描灰色对象的出边
// 如果出边指向的对象还没有被扫描过
if (child != nullptr && !child->is_marked()) {
child->set_marked(); // 记录下它已经被扫描到了
scanning.enqueue(child); // 也把该对象放进灰色队列里等待扫描
}
}
}
}上面两个版本是有且只有一个特殊对象作为根对象的有向图的广度优先遍历。假如不是这样而是有一个集合的引用作为根的话,算法会变为:
void breadth_first_search(Graph* graph) {
// 记录灰色对象的队列
Queue<Node*> scanning;
// 1. 一开始对象都是白色的
// 2. 把根集合的引用能碰到的对象标记为灰色
// 由于根集合的引用有可能有重复,所以这里也必须
// 在把对象加入队列前先检查它是否已经被扫描到了
for (Node* node : graph->root_edges()) {
// 如果出边指向的对象还没有被扫描过
if (node != nullptr && !node->is_marked()) {
node->set_marked(); // 记录下它已经被扫描到了
scanning.enqueue(child); // 也把该对象放进灰色队列里等待扫描
}
}
// 3. 逐个扫描灰色对象的出边直到没有灰色对象
while (!scanning.is_empty()) {
Node* parent = scanning.dequeue();
for (Node* child : parent->child_nodes() { // 扫描灰色对象的出边
// 如果出边指向的对象还没有被扫描过
if (child != nullptr && !child->is_marked()) {
child->set_marked(); // 把它记录到黑色集合里
scanning.enqueue(child); // 也把该对象放进灰色队列里等待扫描
}
}
}
}有没有觉得这算法的样子跟GC越来越像了?
Cheney算法正如上面说的一样,用一个队列来实现对象图的遍历。比较完整的伪代码可以参考我发这节开头给的链接,其中核心的部分抽取出来如下:
void garbage_collect(Heap* heap) {
Semispace* to_space = heap->to_space();
// 记录灰色对象的队列:从scanned到to_space->top()
address scanned = to_space->bottom();
// 1. 一开始对象都是白色的
// 2. 把根集合的引用能碰到的对象标记为灰色
// 由于根集合的引用有可能有重复,所以这里也必须
// 在把对象加入队列前先检查它是否已经被扫描到了
for (Object** refLoc : heap->root_reference_locations()) {
Object* obj = *refLoc;
if (obj != nullptr) {
if (!obj->is_forwarded()) {
// 记录下它已经被扫描到了,也把该对象放进灰色队列里等待扫描
size_t size = obj->size();
address new_addr = to_space->allocate(size);
// address Semispace::allocate(size_t size) {
// if (_top + size < _end) {
// address new_addr = _top;
// _top += size;
// return new_addr;
// } else {
// return nullptr;
// }
// }
// to_space->allocate()移动了to_space->top()指针,
// 等同于scanning.enqueue(obj);
copy(/* to */ new_addr, /* from */ obj, size);
Object* new_obj = (Object*) new_addr;
obj->forward_to(new_obj); // 设置转发指针(forwarding pointer)
*refLoc = new_obj; // 修正指针指向新对象
} else {
*refLoc = obj->forwardee(); // 修正指针指向新对象
}
}
}
// 3. 逐个扫描灰色对象的出边直到没有灰色对象
while (scanned < to_space->top()) {
Object* parent = (Object*) scanned;
// 扫描灰色对象的出边
for (Object** fieldLoc : parent->object_fields()) {
Object* obj = *fieldLoc;
// 如果出边指向的对象还没有被扫描过
if (obj != nullptr) {
if (!obj->is_forwarded()) { // 尚未被扫描过的对象
// 记录下它已经被扫描到了,也把该对象放进灰色队列里等待扫描
size_t size = obj->size();
address new_addr = to_space->allocate(size);
// to_space->allocate()移动了to_space->top()指针,
// 等同于scanning.enqueue(obj);
copy(/* to */ new_addr, /* from */ obj, size);
Object* new_obj = (Object*) new_addr;
obj->forward_to(new_obj); // 设置转发指针(forwarding pointer)
*fieldLoc = new_obj; // 修正指针指向新对象
} else { // 已经扫描过的对象
*fieldLoc = obj->forwardee(); // 修正指针指向新对象
}
}
}
scanned += parent->size();
// 移动scanned指针等同于scanning.dequeue(parent);
}
}它的设计非常精妙:
1. 它使用一块连续的地址空间来实现GC堆,并将其划分为2个半分空间(semispace),分别称为from-space与to-space。平时只用其中一个,也就是from-space;
2. 逐个扫描指针,每扫描到一个对象的时候就把它从from-space拷贝到to-space,并在原来的对象里记录下一个转发指针(forwarding pointer),记住该对象被拷贝到哪里了。要知道一个对象有没有被扫描(标记)过,只要看该对象是否有转发指针即可;
3. 每扫描完一个指针就顺便把该指针修正为指向拷贝后的新对象。这样,对象的标记(mark)、整理(compaction)、指针的修正就合起来在一步都做好了;
4. 它不需要显式为扫描队列分配空间,而是复用了to-space的一部分用作隐式队列。用一个scanned指针来区分to-space的对象的颜色:在to-space开头到scanned指针之间的对象是黑色的,在scanned指针到to-space已分配对象的区域的末尾之间的对象是灰色的。如何知道还有没有灰色对象呢?只要scanned追上了to-space已分配对象区域的末尾就好了。
这种做法也叫做“两手指”(two-finger):“scanned”与“free”。只需要这两个指针就能维护隐式扫描队列。“free”在我的伪代码里就是to_space->top()。
Cheney算法GC工作时,to-space中各指针的样子如下:
|[ 已分配并且已扫描完的对象 ]|[ 已分配但未扫描完的对象 ]|[ 未分配空间 ]|
^ ^ ^ ^
bottom scanned top end在GC结束时,不需要对原本的from-space做什么清理动作,只要把它的分配指针(top)设回到初始位置(bottom)即可。之前在里面的对象就当作不存在了。自然,也就不需要清理其中设置了的转发指针。
要想看图解Cheney算法的工作过程的,请参考这个幻灯片:http://www.ps.uni-saarland.de/courses/gc-ws01/slides/copying_gc.pdf
我现在懒得画图…这个幻灯片已经画得足够好了,直接看它吧。
(不过它所图解的过程跟我的伪代码有一点点细微的差异,别介意…)
后面的回复LeafInWind问道:
LeafInWind 写道
不知理解是否有误,感觉while的条件应该是*scanned==null。
while的条件就是scanned < to_space->top()。或者说条件是scanned != to_space->top()也行。反正就是:如果scanned还没追上to_space->top(),继续循环。
scanned是一个指针,*scanned是一个Object实体。只有指针可以等于null,对象实体就是一个实在的东西,不可能是“null”。
--------------------------------------------------------------
Cheney算法是一个非常非常简单且高效的GC算法。看前面我写的伪代码就可以有直观的感受它有多简单。它的实现代码恐怕比简易mark-sweep还简单。
但为啥很多简易的VM宁可采用mark-sweep而不用Cheney算法的copying GC呢?
因为mark-sweep GC的常规实现不移动对象,而copying GC必须移动对象。移动对象意味着使用GC的程序(术语叫做mutator)需要做更多事情,例如说要能准确定位到所有的指针,以便在对象移动之后修正指针。很多简易VM都偷懒不想记住所有指针的位置,所以无法支持copying GC。
关于找指针的问题,我之前也写过一点:找出栈上的指针/引用
有一种叫做Bartlett风格的mostly-copying GC可以弱化定位指针的需求:根集合之中不需要准确定位指针,只要保守的扫描;在GC堆内的对象则必须要能准确定位其中的指针。有兴趣的可以参考其原始论文:Mostly-Copying Garbage Collection Picks Up Generations and C++
--------------------------------------------------------------
Cheney算法的简单优雅之处来自它通过隐式队列来实现广度优先遍历,但它的缺点之一却也在此:广度优先的拷贝顺序使得GC后对象的空间局部性(memory locality)变差了。但是如果要改为真的深度优先顺序就会需要一个栈,无论是隐式(通常意味着递归调用)或者是显式。
使用递归实现的隐患是容易爆栈,有没有啥办法模拟深度优先的拷贝顺序但不用栈呢?这方面有很多研究。其中一种有趣的做法是IBM的hierarchical copying GC,参考:Improving Locality with Parallel Hierarchical Copying GC
===============================================
相比基本的Cheney算法,HotSpot VM Serial GC有什么异同呢?
相同点:
1. 使用广度优先遍历;
2. 使用隐式队列;
3. copy等同mark + relocate (compact) + remap (pointer fixup)三件事一步完成。
在HotSpot VM里,copying GC用了scavenge这个名字,说的是完全相同的事。
相异点:
1. 基本Cheney算法不分代,而HotSpot的GC分两代
2. 基本Cheney算法使用2个半分空间(semispace),而HotSpot的GC在young generation使用3个空间——1个eden与两个survivor space。注意这两个survivor space就与semispace的作用类似。
在G1 GC之前,所有HotSpot VM的GC堆布局都继承自1984年David Ungar在Berkeley Smalltalk里所实现的Generation Scavenging。参考论文:Generation Scavenging: A Non-disruptive High Performance Storage Reclamation Algorithm
GC堆布局:
那我们一点点把基本的Cheney算法映射过来。
* 基本Cheney算法用from-space和to-space,而HotSpot VM的DefNewGeneration有三个空间,eden space、from-space、to-space。后者的eden space + from-space大致等于前者的from-space,而后者的to-space + old gen的一部分大致等于前者的to-space。
* 拷贝对象的目标空间不一定是to-space,也有可能是old generation,也就是对象有可能会从young generation晋升到old generation。
为了实现这一功能,对象头的mark word里有一小块地方记录对象的年龄(age),也就是该对象经历了多少次minor GC。如果扫描到一个对象,并且其年龄大于某个阈值(tenuring threshold),则该对象会被拷贝到old generation;如果年龄不大于那个阈值则拷贝到to-space。
要留意的是,基本Cheney算法中2个半分空间通常一样大,所以可以保证所有from-space里活着的对象都能在to-space里找到位置。但HotSpot VM的from-space与to-space通常比eden space小得多,不一定能容纳下所有活的对象。如果一次minor GC的过程中,to-space已经装满之后还遇到活对象要拷贝,则剩下的对象都得晋升到old generation去。这种现象叫做过早晋升(premature tenuring),要尽量避免。
* 既然拷贝去的目标空间不一定是to-space,那原本Cheney算法里的隐式扫描队列会在哪里?
答案是既在to-space,也在old generation。很简单,在这两个空间都记录它们的scanned指针(叫做“saved mark”),这俩空间各自原本也记录着它们的分配指针(“top”),之间的部分就用作扫描队列。
* Forwarding pointer安装在对象(oopDesc)头部的mark word(markOop)里。只有在minor GC的时候才会把已拷贝的对象的mark word借用来放转发指针。
* 通过回调,把遍历逻辑与实际动作分离。例如说,遍历根集合的逻辑封装在GenCollectedHeap::gen_process_strong_roots()、SharedHeap::process_strong_roots()里,遍历对象里的引用类型字段的逻辑封装在oopDesc::oop_iterate()系的函数里;而实际拷贝对象的动作则由FastScanClosure::do_work()负责调用。
* 基本Cheney算法的“scanned”指针,在HotSpot Serial GC里是每个space的“saved mark”。相关操作的函数名是:“save_marks()” / “set_saved_mark()”、“reset_saved_mark()”、“no_allocs_since_save_marks()” / “saved_mark_at_top()”
看看遍历循环的结束条件(循环条件的反条件):
bool saved_mark_at_top() const { return saved_mark_word() == top(); }跟基本Cheney算法的循环条件 scanned != top() 一样。
为啥我的伪代码里scanned是个局部变量,而HotSpot里变成了每个空间的成员字段?因为使用回调函数来分离遍历逻辑与实际动作,代码结构变了,这个scanned指针也只好另找地方放来让需要访问它的地方都能访问到。
* HotSpot VM的分代式GC需要通过写屏障(write barrier)来维护一个记忆集合(remember set)——记录从old generation到young generation的跨代引用的数据结构。具体在代码中叫做CardTable。在minor GC时,old generation被remember set所记录下的区域会被看作根集合的一部分。而在minor GC过程中,每当有对象晋升到old generation都有可能产生新的跨代引用。
所以FastScanClosure::do_work()里也有调用写屏障的逻辑:OopsInGenClosure::do_barrier()。
* HotSpot VM要支持Java的弱引用。在GC的时候有些特殊处理要做。可以参考这帖:http://hllvm.group.iteye.com/group/topic/27945?page=2#post-209812
* HotSpot VM的GC必须处理一些特殊情况,一个极端的例子是to-space和old generation的剩余空间加起来都无法容纳eden与from-space的活对象,导致GC无法完成。这使得许多地方代码看起来很复杂。但要了解主要工作流程的话可以先不关心这些旁支逻辑。
--------------------------------------------------------------
HotSpot代码与我的伪代码的几个对应关系:
HotSpot => 我的Cheney算法伪代码
* saved mark => scanned
* FastScanClosure => process_reference()
* GenCollectedHeap::gen_process_strong_roots()、SharedHeap::process_strong_roots() => 遍历根集合的循环逻辑
* FastEvacuateFollowersClosure => 遍历扫描队列的循环
* oopDesc::oop_iterate() => 遍历对象的引用类型字段的循环,Object::object_fields()
* DefNewGeneration::copy_to_survivor_space() => 拷贝对象的逻辑,Heap::evacuate()
其它应该都挺直观的?
===============================================
Oracle Labs的Maxine VM里也有过Cheney算法的实现,在这里:https://kenai.com/projects/maxine/sources/maxine/content/com.oracle.max.vm/src/com/sun/max/vm/heap/sequential/semiSpace/SemiSpaceHeapScheme.java?rev=8747
也可以参考来看看。纯Java实现的GC喔。
===============================================
顺带一提,早期V8的分代式GC中的minor GC也是基于Cheney算法,而且更接近原始的基本算法——只用2个半分空间。最大的区别就是由于是分代式GC的一部分,它也跟HotSpot一样要处理对象晋升和写屏障。
Jay Conrod:A tour of V8: Garbage Collection(中文翻译:V8 之旅: 垃圾回收器)
就先写这么多了⋯


